

A while ago, I wrote about the new python AI Agent library called Browser Use. Back then it had just about 5000 stars on github. Now the repository is at over 20,000 stars on github. If you’re reading this, it is because you want to build something cool with browser-use.
My idea is to build more predictable scenarios and automation using AI Agents. So I am leaning on the concept of job queuing or task queuing to produce a predictable outcomes. Job queues also allow me to isolate each AI Agents operation. This also gives me control and insight over what operation I can tweak or repeat or throttle. In a production environment, predictability also means stability.
Browser-use is a python library. Celery is a python job queue. Lets have babies. I initially started the project by checking out some github repositories that implement job queues in python. I wanted to find out some common practices, basic job queue todos, anything python job queues I should catch up on.
Redis and Flower
To implement a job queue, I need a storage backend or a database. In the past, I have built job queues in Nodejs using libs like Bull and Kue, so I can say I have experience with the concept. Job queues can support popular databases like MongoDB, Postgres, MySQL and Redis. Redis is the best database for job queues in most cases.
I noticed the top and recently updated repositories included a docker compose file and also had a Flower service definition included in the file. Flower Monitoring Service is an open-source web application for monitoring and managing Celery clusters.
Installing the project dependencies.
I started out the project using this repository as a foundation. The readme files explains how to easily setup a celery project using a bash script and command.
#!/usr/bin/env bash
sudo docker-compose -f docker-compose.yml up --scale worker=2 --buildThis will start 3 docker containers. Once the containers are up, you can access the following services:
- FastAPI REST API ( Not needed ): Access the FastAPI application by navigating to http://localhost:8000 in your web browser or using tools like curl or Postman.
- Flower Monitoring Dashboard: Monitor the Celery tasks and workers by visiting http://localhost:5555 in your web browser.
- Redis: Redis, used as both backend and broker, is accessible internally within the network
Overall, the dependencies for the project are:
- Redis database and python library.
- Celery python library and flower.
- Browser-use
On a fresh python project, install browser-use, celery and redis. I want to use poetry as the package manager for this project.
poetry new poetry-demoAdd the dependencies
poetry add redis celery browser-use load_dotenv
Project Folder Structure
.
├── poetry-demo
│ ├── app
│ │ ├── browsers
│ │ │ ├── browser.py
│ │ │ └── __pycache__
│ │ │ └── browser.cpython-311.pyc
│ │ ├── celery.py
│ │ ├── config.py
│ │ ├── helpers
│ │ ├── projects
│ │ │ └── xhandles
│ │ │ ├── agents
│ │ │ │ └── search_x_prospects.py
│ │ │ ├── prompts
│ │ │ │ └── search.py
│ │ │ ├── tasks
│ │ │ │ └── search_x_prospects.py
│ │ │ └── types.py
│ │ ├── __pycache__
│ │ │ └── celery.cpython-311.pyc
│ │ └── types.py
│ ├── __init__.py
│ └── __pycache__
│ └── __init__.cpython-311.pyc
├── poetry.lock
├── pyproject.toml
├── README.md
└── tests
└── __init__.py- app/projects/{project_name}/agents/* and app/projects/{project_name}/tasks/* : I am choosing to group my
agentsandtasksunder a project folder. - app/projects/{project_name}/helpers/*: I have a folder for utilities and
helperfunctions and classes. - app/projects/{project_name}/prompts/*: I have a folder for prompts which are functions that return a prompt for a tasks or job.
- app/projects/{project_name}/browsers/*: Configuration for different browsers and browser profiles my AI Agents can launch when ready.
- app/config.py: Holds config values and constants
- app/types.py: I define all my structured output classes and pydantic models here.
- app/celery.py: A celery worker that handles connecting to redis and managing the tasks queue.
- .env: Environment variables
OPENAI_API_KEY=sk-jDppPlxxxxxxxxxxxxxxxxxxxx
REDISSERVER=redis://localhost:6379Create a celery worker
Celery needs to connect to redis and handle tasks. A worker communicates with a broker and a backend which could be different messaging systems or databases. In this case, I am using Redis.
import os
from celery import Celery
from dotenv import load_dotenv
load_dotenv()
# celery broker and backend urls
CELERY_BROKER_URL = os.getenv("REDISSERVER", "redis://localhost:6379")
CELERY_RESULT_BACKEND = os.getenv("REDISSERVER", "redis://localhost:6379")
# create celery application
celery = Celery(
'tasks',
backend=CELERY_BROKER_URL,
broker=CELERY_RESULT_BACKEND,
include=[],
)
if __name__ == '__main__':
celery.start()Run the Celery Worker
poetry run celery -A poetry_demo.app worker --loglevel=info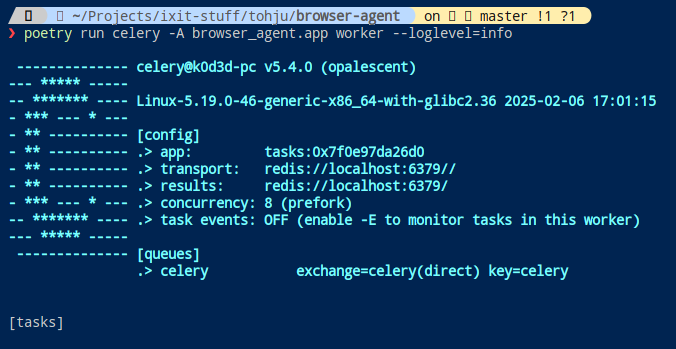
This, done successfully, takes care of dependencies and setup todos. I can now focus on coding a solution to my problem: scrape handles and bio from X.
Introducing the Problem: Automation
I want to gather a list of twitter profiles and the profile bio. By outlining the stages of gathering twitter / X profiles,
I can progress to writing out the logic required in each stage.
- Automation:
- Pipeline:
- Search Prospects
- Get Prospect Urls
- Visit and Analyze Prospect Profile.
- Pipeline:
Each stage is like a task or job on the job queue. The job queue can be designed as a linear pipeline where one stage calls the immediate next stage and so on. It can also be designed to have branches where a job can call multiple job an X number of times and it cascades on.
Define the AI Agents and Tasks.
Each stage or tasks will need AI Agents, Tasks and a prompt defined. To implement a solution for Stage A: Search Prospect, I need to create an agent, then define a tasks.
1. Starting out with the agent.
import os
import sys
from app.browsers.browser import init_browser
from app.types import SearchProspectsResult
from langchain_openai import ChatOpenAI
from browser_use import Agent, Controller, ActionResult
from app.prompts import get_search_result_profiles
from app.config import app_config
controller = Controller()
@controller.registry.action('Done with task', param_model=SearchProspectsResult)
async def done(params: SearchProspectsResult):
result = ActionResult(is_done=True, extracted_content=params.model_dump_json())
return result
def create_twitter_prospects_agent() -> Agent:
# Customize these settings
llm = ChatOpenAI(model=app_config.model, api_key=app_config.openai_api_key)
# Create the agent with detailed instructions
return Agent(
task=get_search_result_profiles(
url='https://x.com/search?q=(chatgpt%20OR%20is%20OR%20down%20OR%20frustrated%20OR%20cancelling)&src=typed_query',
count=30
),
llm=llm,
controller=controller,
# use_vision=True,
browser=init_browser(),
)
The create_twitter_prospects_agent function creates an agent that can be used to search for prospects on Twitter. The done function is likely used to handle the completion of a task and return the results. The API for getting structured output has been updated since I made this post. I can now add a model_output argument to the Controller class with a pydantic model. This code still works. This is using browser-use and AI agents, now lets add in celery stuff.
Creating a celery tasks
async def perform_search(agent):
try:
# await agent.run(max_steps=100)
history = await agent.run(max_steps=100)
result = history.final_result()
except Exception as e:
print(f"Error posting tweet: {str(e)}")
return result
@celery.task(name="search.prospects", bind=True)
def search_prospects(self):
# return result
agent = create_twitter_prospects_agent()
result = asyncio.run(perform_search(agent))
if not result:
return {'result': 'no results'}
parsed = SearchProspectsResult.model_validate_json(result)
get_prospect_urls.delay(parsed.author_handles,)
return resultThe search_prospects function is designed to run in the background using Celery and performs the following tasks:
- Creates a Twitter prospects agent.
- Runs the agent to perform a search.
- Validates the result and extracts the author handles.
- Delays the execution of
get_prospect_urlswith the author handles.
The Task Prompt
def get_search_result_profiles(url, count):
return f"""Collect {count} user handles from the search results page
Here are the specific steps:
1. Go to {url}.
2. Notice the user handle for each posts author profile
3. Collect {count} user handles or usernames.
"""This is the instruction you want the AI Agent to carry out. To get structured output as a result, I have defined my model in my types.py file.
class SearchProspectsResult(BaseModel):
author_handles: List[str]This, so far, covers what I need to accomplish the first stage in the job queue. The next stages require the same basic files for an agent, tasks and a prompt. Well, the 2nd stage or task: Get Prospect Urls does not require an AI Agent.
2. Get Prospect Urls Task
@celery.task(name="get.prospect.urls", bind=True)
def get_prospect_urls(self, result: List[str]):
# loop over result.author_handles
for handle in result:
visit_profile.delay(handle, )
return TrueThe first stage, search prospects, returns a list of author_handles which is basically an array of strings. I am looping over the array and creating jobs to visit the handles’ profile.
3. Visit and Analyze Prospect Profile.
This code here creates an AI Agent that carries out the task defined in visit_analyze_profile_on_twitter.
controller = Controller()
@controller.registry.action('Done with task', param_model=WebsiteAnalysisReq)
async def done(params: WebsiteAnalysisReq):
result = ActionResult(is_done=True, extracted_content=params.model_dump_json())
return result
@controller.registry.action('Get Post Url')
async def get_post_url(browser: BrowserContext):
page = await browser.get_current_page()
return ActionResult(extracted_content=page.url)
def create_visit_x_profile_agent(handle) -> Agent:
llm = ChatOpenAI(model=app_config.model, api_key=app_config.openai_api_key)
# Create the agent with detailed instructions
return Agent(
task=visit_analyze_profile_on_twitter(
handle,
),
llm=llm,
controller=controller,
# use_vision=True,
browser=main_browser,
)
Here is the prompt for the AI Agents task.
def visit_analyze_profile_on_twitter(handle):
return f"""
Visit the profile page of https://x.com/{handle} on Twitter.
Analyze the profile bio.
Visit https://x.com/search?q=(crypto%20OR%20ai%20OR%20llm%20OR%20web3%20OR%20developer)%20(from%3A{handle})%20min_replies%3A5%20min_faves%3A10%20min_retweets%3A1&src=typed_query .
Analyze the top tweets and select a tweet you want to reply to that is related to Web3, AI or LLMs.
Click on the tweet and wait for the next page to load.
Get the Url of the tweet.
"""Browser-use has since introduced initial actions. This improves things like opening a tab or scrolling a page before the AI Agent starts to operate.
Heres the code for the celery task.
async def perform_analysis(agent):
try:
# await agent.run(max_steps=100)
history = await agent.run(max_steps=100)
result = history.final_result()
except Exception as e:
print(f'Error posting tweet: {str(e)}')
return result
@celery.task(name="visit.profile", bind=True, rate_limit="2/m")
def visit_x_profile(self, handle: str):
agent = create_visit_x_profile_agent(handle)
result = asyncio.run(perform_analysis(agent))
if not result:
return {'result': 'no results'}
analysisReq = WebsiteAnalysisReq.model_validate_json(result)
return {
'profile_analysis': analysisReq.profile_analysis,
'tweet_url': analysisReq.tweet_url,
'tweet_content': analysisReq.tweet_content
}The output schema, WebsiteAnalysisReq is,
class WebsiteAnalysisReq(BaseModel):
tweet_url: str = ""
tweet_content: str = ""
profile_analysis: str = ""Add or Include your tasks in your worker.
Remember your app/celery.py . Yeah the one that starts the Celery worker. Add the paths to your defined tasks in the include array.
...
broker=CELERY_RESULT_BACKEND,
include=[
'poetry_demo.app.projects.myproject.tasks.search_x_prospects',
'poetry_demo.app.projects.myproject.tasks.get_prospect_urls',
'poetry_demo.app.projects.myproject.tasks.visit_x_profile',
],
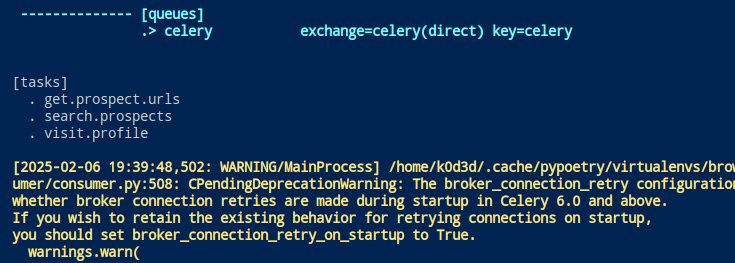
...Then kill the worker process and restart it. You should see your tasks in the log
Create a main.py file.
The last thing should be creating an entry file at poetry-demo/main.py.
from dotenv import load_dotenv
load_dotenv()
from tasks.twitter.search_prospects import search_prospects
def main():
task = search_prospects.delay()
print(task)
if __name__ == "__main__":
main()Running the job queue
I will keep the worker instance running and run the job queue using poetry run.
poetry run python poetry_demo/main.py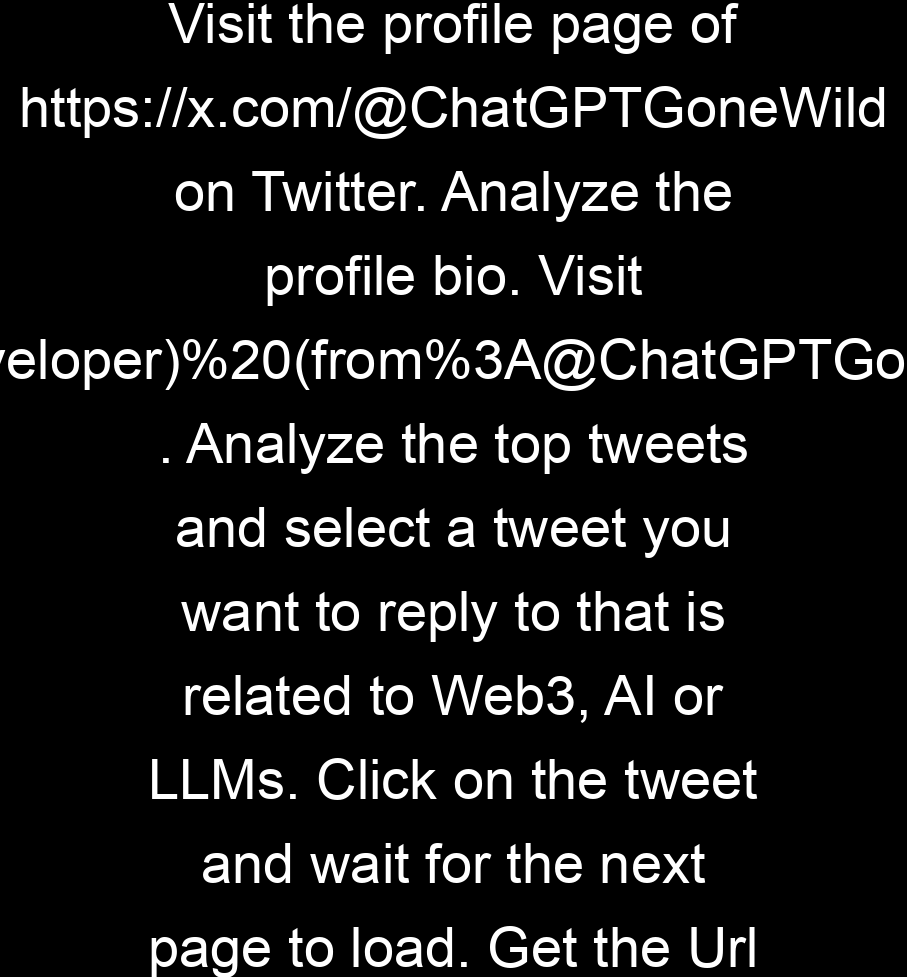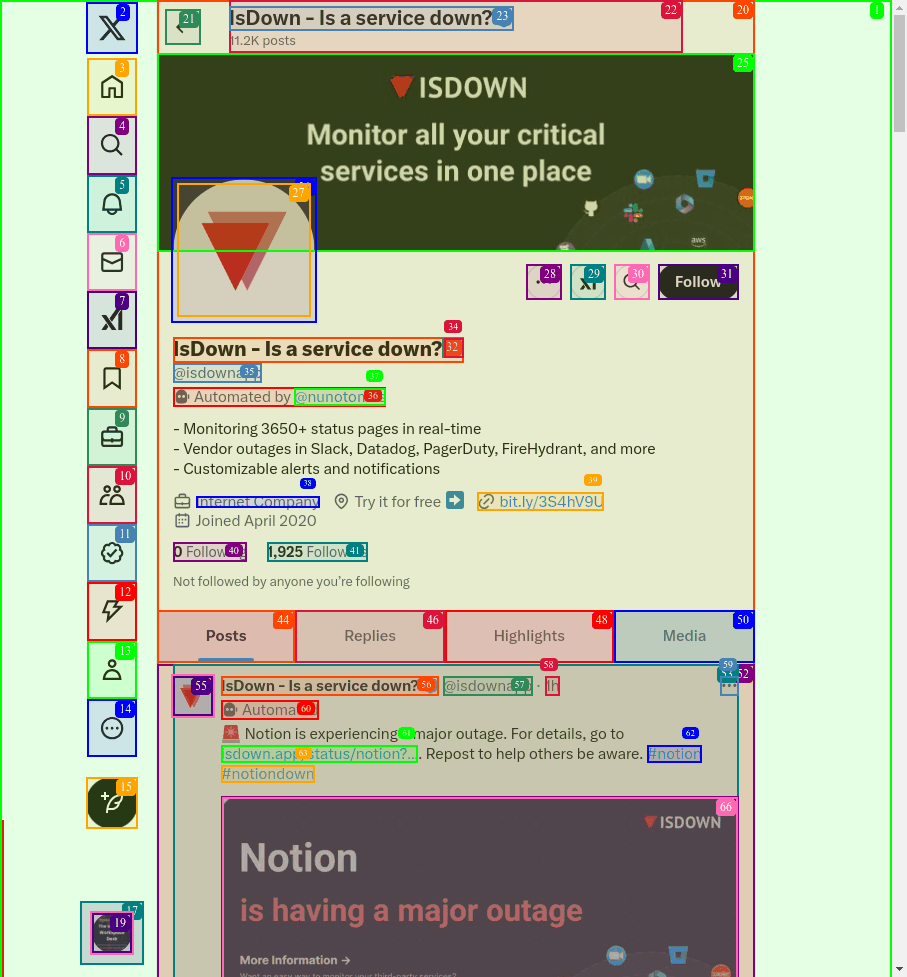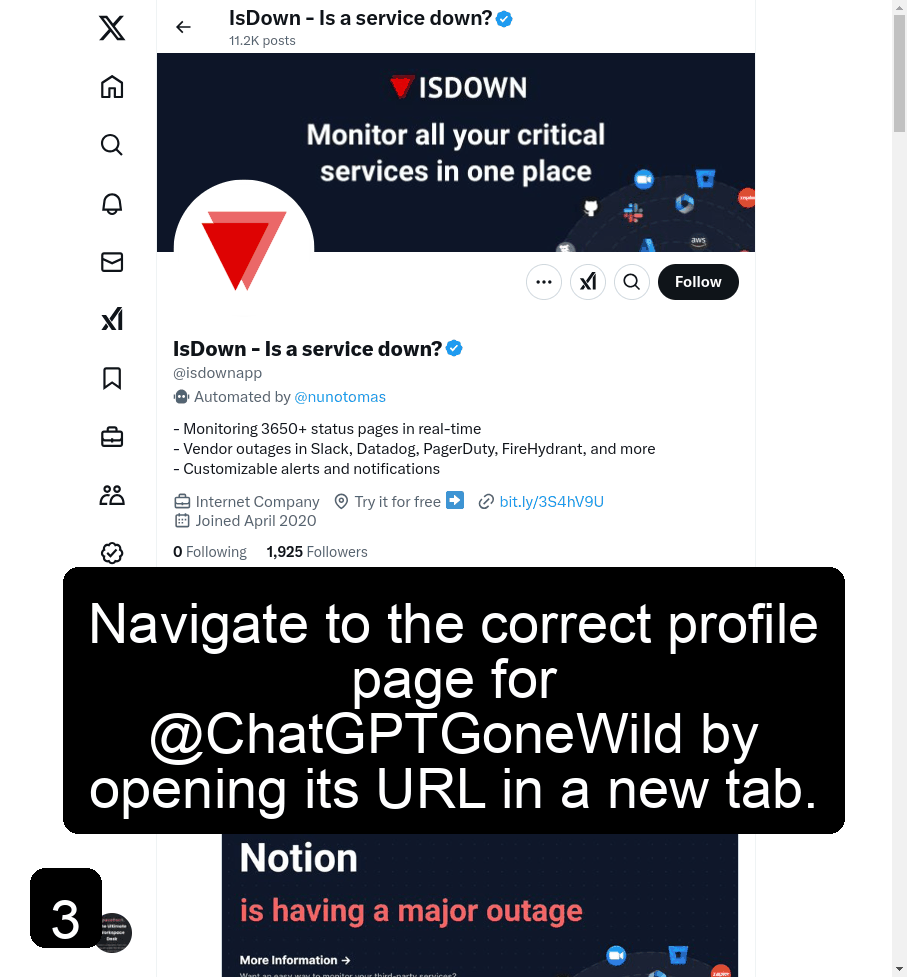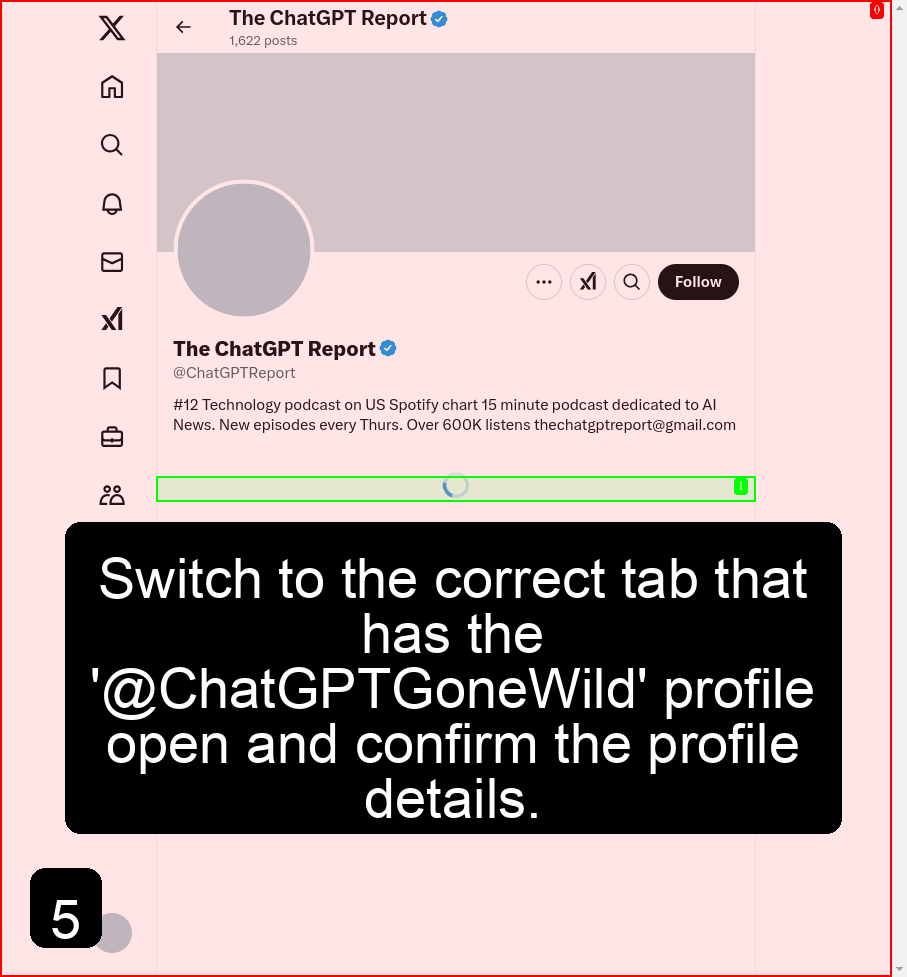
Not to be pessimistic, but things hardly run out smooth the first time. If you are lucky to have this simple setup running without errors.
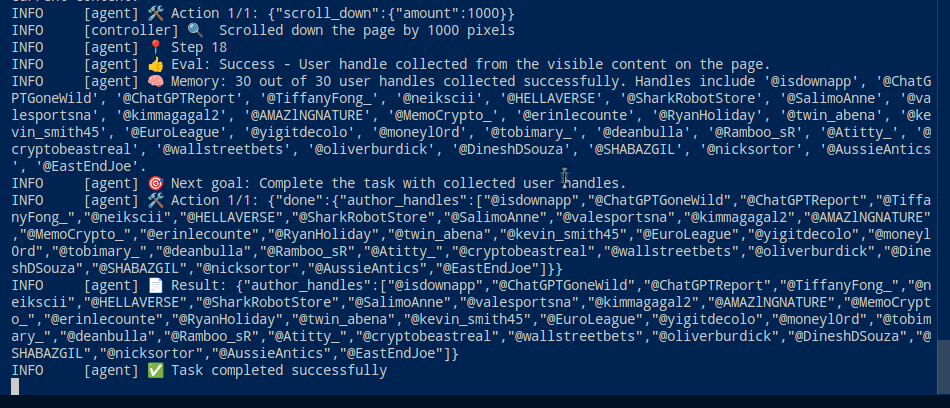
For now, I am satisfied with the results. The AI Agent gets to collect the specified number of handles as stated in the tasks description on the first stage / task.
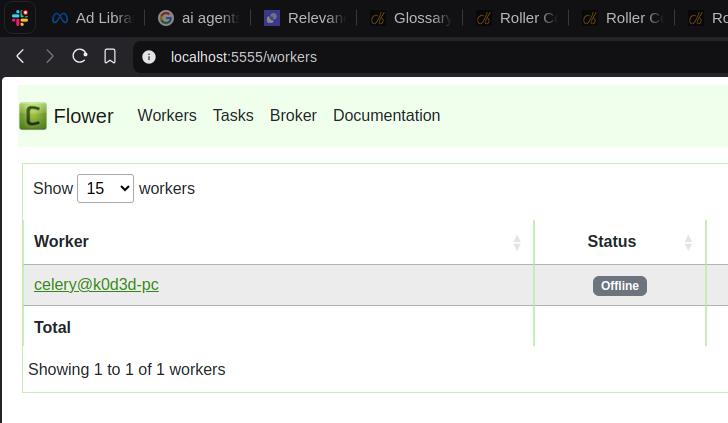
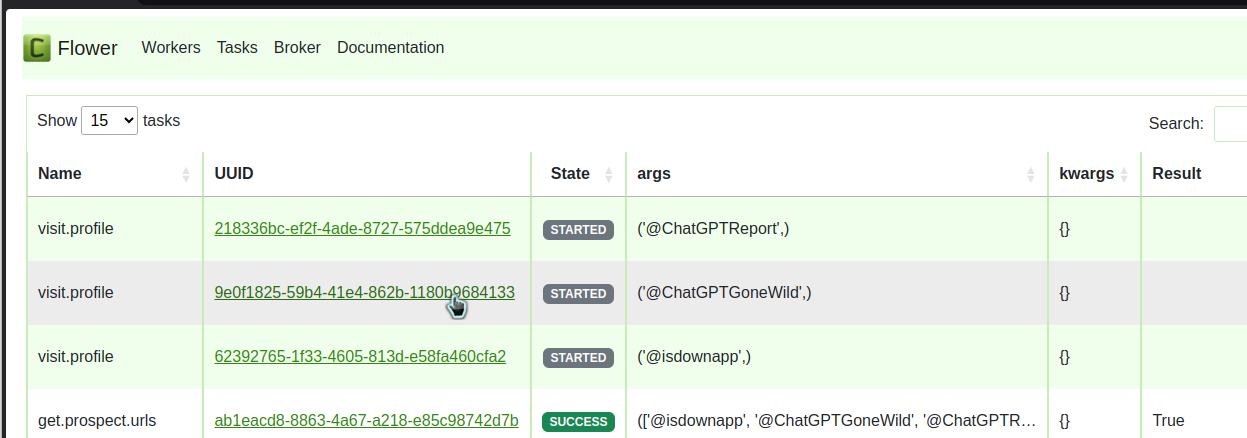
I can also check Flower for the status of the jobs put on the queue.
I plan to improve this implementation to manage the number of open tabs the AI Agent creates so my computer does not run out of memory. When I deploy this to a server, I will have the browser operate in headless mode. That way I do not need the window launched.
Thank you for reading this far. 🙏
Here is a link to the code on Github
Do You Know 💵
Tohju.com is giving out $5 free to run any AI model you can find on Replicate.com . You can find hundreds of models that do Image, Video and even music generation. You do not need to subscribe, just pay for what you create. If you are a freelancer or agency just starting out, this is a great plan for you.